Entity Framework provides a way to create a model from the existing database. It’s called “Database First”. For this note, I will give a simple example to indicate how to do it.
First, create a database called “DatabaseFirstTest”, and run the following SQL scripts to create the testing data.
------------------------------------------------
/* Tables */
CREATE TABLE Brand(
BrandId int NOT NULL PRIMARY KEY,
Name varchar(255) NOT NULL
);
GO
CREATE TABLE Car(
CarId int NOT NULL PRIMARY KEY,
BrandId int NOT NULL REFERENCES Brand(BrandId),
);
GO
CREATE TABLE Person(
PersonId int NOT NULL PRIMARY KEY,
Name varchar(255) NOT NULL,
);
GO
CREATE TABLE PersonCar(
PersonId int NOT NULL EFERENCES Person(PersonId),
CarId int NOT NULL EFERENCES Car(CarId),
PRIMARY KEY(PersonId, CarId)
);
GO
/* Seeding */
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('1'
,'BMW')
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('2'
,'Jeep')
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('3'
,'Audi')
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('4'
,'GMC')
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('5'
,'Lexus')
INSERT INTO [dbo].[Brand]
([BrandId]
,[Name])
VALUES
('6'
,'Mazda')
GO
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('1'
,'1')
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('2'
,'2')
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('3'
,'3')
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('4'
,'3')
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('5'
,'1')
INSERT INTO [dbo].[Car]
([CarId]
,[BrandId])
VALUES
('6'
,'1')
GO
INSERT INTO [dbo].[Person]
([PersonId]
,[Name])
VALUES
('1'
,'Frank')
GO
INSERT INTO [dbo].[Person]
([PersonId]
,[Name])
VALUES
('2'
,'Jake')
GO
INSERT INTO [dbo].[Person]
([PersonId]
,[Name])
VALUES
('3'
,'Mike')
GO
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('1'
,'1')
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('1'
,'2')
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('2'
,'3')
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('2'
,'4')
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('3'
,'5')
INSERT INTO [dbo].[PersonCar]
([PersonId]
,[CarId])
VALUES
('1'
,'6')
GO
/* Stored Procedure */
CREATE PROCEDURE spGetCarsInformationByPerson
@PersonName nvarchar(50)
AS
SELECT
b.Name as CarBrandName,
Count(b.Name) as CountOfCars
FROM Person p
JOIN PersonCar pc on p.PersonId = pc.PersonId
JOIN Car c on pc.CarId = c.CarId
JOIN Brand b on c.BrandId = b.BrandId
WHERE p.Name = @PersonName
Group by b.Name
GO
------------------------------------------------
Then there are four tables and one stored procedure added to our database.
From this SQL scripts, we can see that Car and Brand is 1-to-Many relationship. Also, it is Many-to-Many relationship between Car and Person. (we assume that many persons could share the same car…and person can own multiple cars)
Second, create a console application and install Entity Framework.
a. Select console App
b. On top menu bar, select Tools -> NuGet Package Manger -> Manage NuGet Packages for Solution…
c. Select EntityFramwork and install it to our project.
Third, we will add the Entity Data Model to our project
a. Right click the current project and select Add -> New Item
b. Then, select “EF Designer from database”
c. Click -> New connection to setup connection detail
d. Mark all tables and store procedures, and click finish
e. Then we can see a diagram created by EF.
Then, we can start to analyze what EF has done for us.
a. On our project folder, previous diagram is bound to EDMX file.
b. If you want to see the detail of this file, you can right-click that EDMX file, and open with XML format.
It seems scared for too much information on previous picture. I will explain it briefly.
a. Definition
SSDL: Store schema definition language
CSDL: Conceptual schema definition language
MSL(C-S mapping): Mapping specification language
b. To make it clear, you can think SSDL is the model of database, and CSDL is the model of entity. And MSL is used to describe how to map model of database and model of entity. If you still feel confused, click “
HERE” to get more information.
c. Also, if you update model from database, and you have some changes, such as delete tables, delete fields, rename fields, or change attribute of fields, then SSDL will be update, but CSDL will not be updated. You need to modify CSDL manually.
We can do a quick experiment to see what happens for SSDl, CSDL, and MSL.
a. Let change the table name from Car to Vehicle. Also, change the CarId to VehicleId.
b. Then open EDMX file again.
c. For SSDL, there is no any changes.
d. For CSDL, we found that its name has been changed to Vehicle!
e. For MSL, we can find that it indicates that Entity Vehicle should bind to model Car. Also, VehicleId will bind to CarId as well.
It also provides a visual way to view models.
Just right click the EDMX diagram and select Model Browser. Then you can see the different models from entity or database separately.
Also, you can change the mapping by right click entity from EDMX file, and select “Table Mapping”
Now, we will give an example to show how to use our stored procedure.
a. Paste the following codes on Program.cs
------------------------------------------------
var dbContext = new
DatabaseFirstTestEntities();
var list =
dbContext.spGetCarsInformationByPerson("Frank");
foreach (var item
in
list) {
Console.Write("Brand: {0}, Count: {1}\n",
item.CarBrandName,
item.CountOfCars);
}
------------------------------------------------
b. Then, you can see the result as following.
c. If you execute the following command in database, you will get the same result.
------------------------------------------------
EXECUTE spGetCarsInformationByPerson @PersonName = N'Frank'
------------------------------------------------
d. Both results are the same!
However, you might notice that in C#, we do not name function starting with lower case. We also can change it.
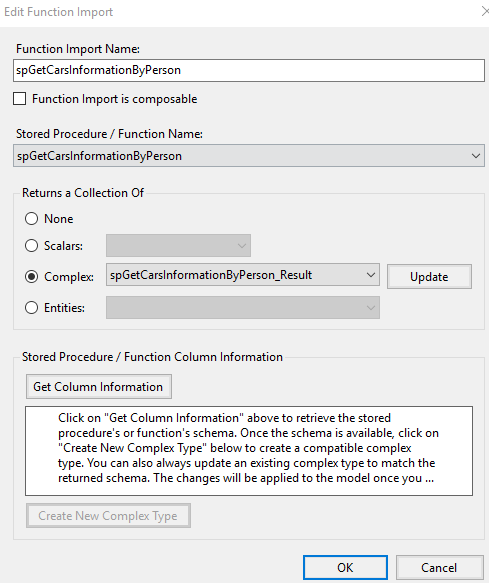
a. On Model Browser, double click spGetCarsInformationByPerson function, then it will pop-up a window to let you edit its name or modify the binding.
b. After that, you can use dbContext.GetCarsInformationByPerson function and trigger the spGetCarsInformationByPerson on database.
According above, we learn how to use database-first to create model in our project!